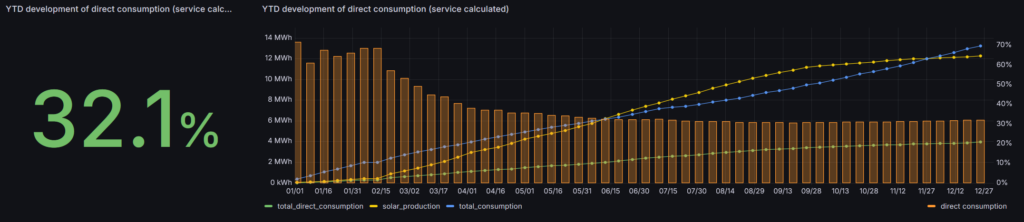
2025 has passed months ago. I have not taken the time to evaluate the performance of my energy consumption goals.
The situation also didn’t change that much compared to previous year.
I closed the year with a direct consumption of 32.1%. This is very close to the 34.1% of 2024. I’m far away from my goal of 45%. Unfortunately this looks like this is the best I can do based on my current technical set-up and consumption patterns.
Let’ have a look at the car charging and heatpump planning numbers.
Car charging
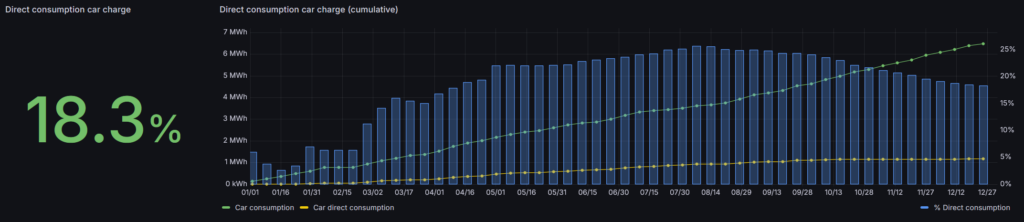
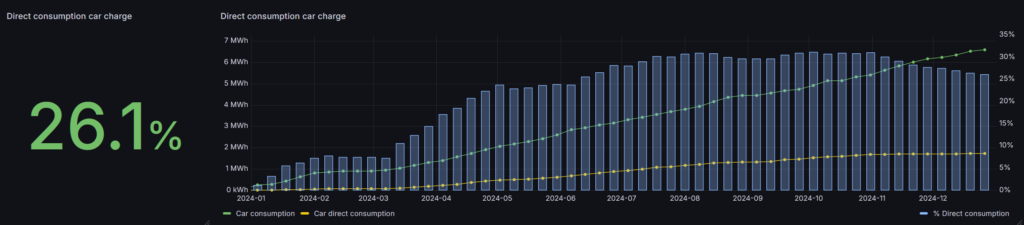
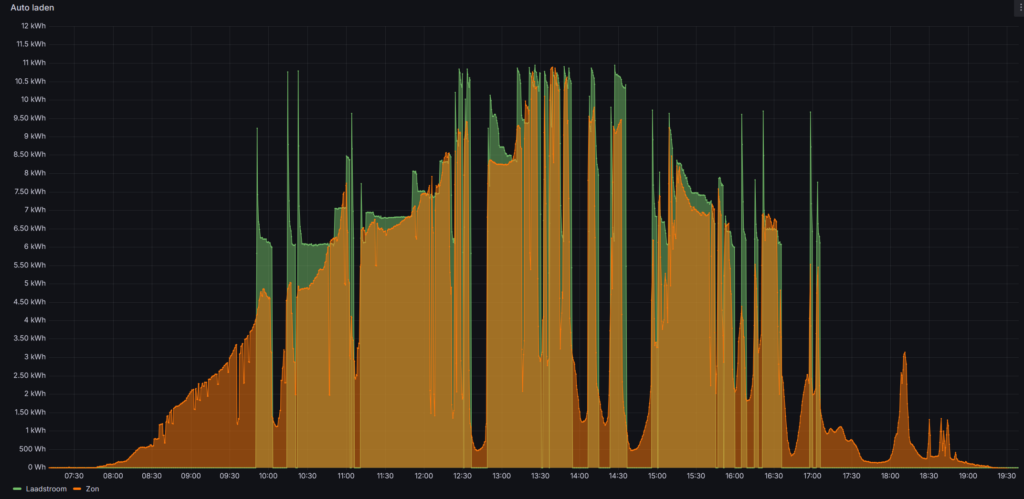
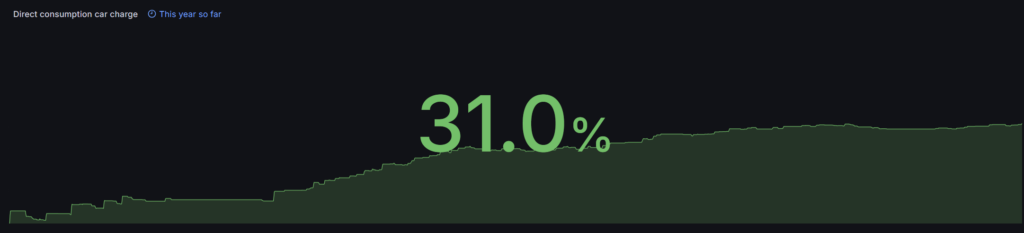
This is where things went “wrong”. In total the car consumed 6400kWh in 2025, which is more or less the same as 2024. 1171kWh was produced by solar energy, compared to 1730kWh (26.1%) in 2024.
We are using the car during the day and therefore need to charge it during the night. There is little more to improve here, other than postponing the charge as much as possible when we know we don’t have to use the car the next day.
Heatpump planning
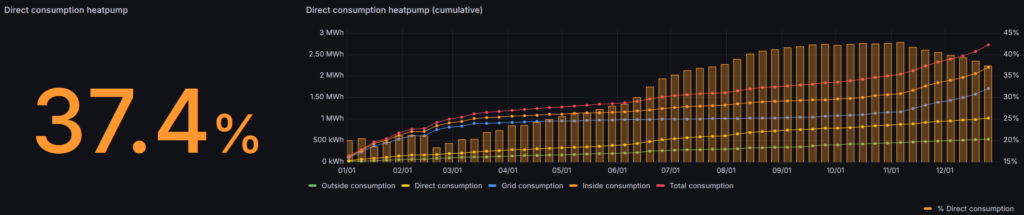
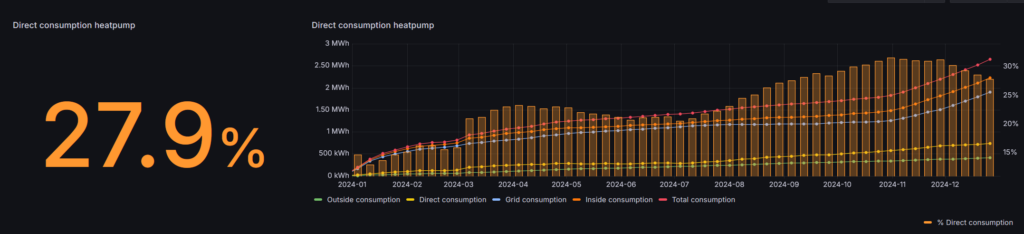
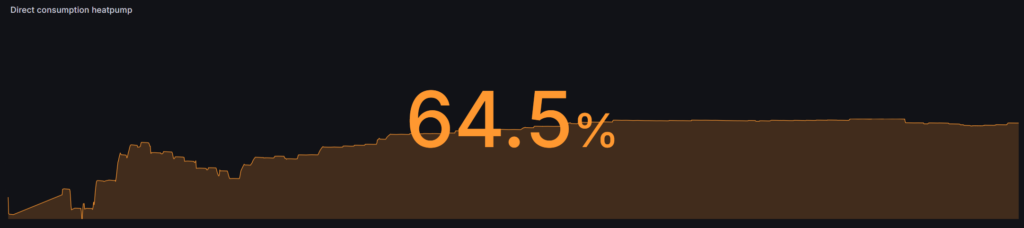
Finally some good news! In total the heatpump consumed 2724kWh (2596 degree days) over 2025 (compared to 2650kWh in 2024, 2426 degree days). The direct consumption went up from 27.9% in 2024 to 37.4% in 2025.
The algorithm changes in the last part of 2025 seem to have worked over 2026. I’m curious to see how this will develop over to 2027.
Overview
I need to look into the 8% drop of direct consumption by the car, and the limited impact on the total direct consumption (even though the car is contributing to roughly 50% of our entire consumption).
Year
Direct Consumption
Car
Heatpump
2023
19%
n.a.
n.a.
2024
34%
26%
28%
2025
32%
18%
37%
Looking forward
I’ve kept an eye on these number during 2025 and already concluded I’ve reached the limits of the current way of working. I started to consider purchasing a home battery in October. I was hoping to find a 3-phase system that would be able to flexibly deliver energy on all three phases. I couldn’t find a system what would be able to do this. My next chain of thought was to purchase three 1-phase systems, but that would mean an investment of over 10.000 EUR on technology of which I don’t know if it helps me to achieve my goals and how long it will last.
Eventually, I decided to purchase one 1-phase system with roughly 9kWh of capacity: the Zendure AC2400 with three batteries.
They had a good end of the year deal and after some fiddling around with their API I managed to integrate the system into the digital twin of my house. As it’s a 1-phase system I’m just looking at the total consumption and delivery of the 3-phases. The battery charging strategy works based on the EPEX energy price and the predicted amount of solar energy for the upcoming day. If the amount of solar energy is large enough, it waits until the peak moment of the day and then starts charging at full speed. When the difference between the highest and lowest energy price meets a certain threshold, it charges at full speed during the lowest point. Last, when predictions are bad, it just prevents energy from being delivered back to the grid.
For now this is working, but I’m sure I will need the rest of 2026 to optimize the charging and discharging strategy. I am already seeing an impact on my energy dependency but I still need to analyze the data and think of a good KPI to monitor the progress.
Based on the technical architecture of my digital home I’m currently running 42 micro-services. Each micro-service has a special role in our daily lives. This article provides an overview of the use-cases that these micro-services enable.
I have multiple goals with these use-cases:
Comfort: automating daily routines, especially the ones that are highly repetitive and require extensive steps;
Reducing energy cost: we have a fully electric house (with the exception of the second car) and consume a lot of energy. Prices are dynamic and with planning our consumption we can reduce our energy cost;
Reducing grid load: we are living in an electrified environment (with the exception of the second car) and consume a lot of energy. We try to consume energy outside of grid congestion hours (between 16.00 and 21.00) and take the availability of solar energy into account.
It's important to understand I'm using a price index to select the best moment of the day to consume energy. I calculate the price index based on the EPEX energy prices and the expected amount of solar energy.
Heating optimization: when winter comes I calculate the expected number of hours the heatpump requires to keep our home comfortable. Based on the energy price index the heatpump is switched on. Additionally, when a lot of sun is expected heating is disabled and the sun heates up our home during the morning, sometimes reaching a comfortable 21C when it’s freezing outside;
Hot water optimization: hot water generation is planned based on the current water temperature and the energy price index;
Ventilation optimization: we have six CO2 sensors in our home. The ventilation system is controlled based on the input of the CO2 sensors. The ventilation slows down when we are not at home to save energy in the ventilation system itself as well as heating losses;
Car charging planning: car charging is planned based on the planned time to leave the next day, battery charge state and the energy price index;
Appliance planning: the dishwasher, washer and dryer programs are planned based on the time of the day the program is being started and the energy price index;
Security alarm system: the security alarm system is automatically armed when we leave. Camera snapshots are send to our mobile devices when the virtual perimeter alarms are triggered, motion detectors are triggered, or when persons approach the front door;
Light control: lights are automatically controlled based on the time of day, position of the sun (season), motion detectors, and state of the security alarm system;
Solar screen control: solar screens are automatically controlled based on the weather predictions and inside temperature;
Beer/drinks fridge control: our outside fridge only turns on on Friday, Saturday and Sunday when temperatures reach over 20C and sun is expected;
Radio automated start: this was an annoyance: the radio is automatically started when the Chromecast comes online. No more apps to manually control the radio. In the weekend another radio channel is selected to switch from working to weekend mode;
Energy monitoring: 50 energy monitoring sensors ranging from the consolidate building energy consumption, freezer, fridge, lighting, car, heatpump, solar panels, TV and IT equipment.
Automatically turn off solar energy production when energy prices are negative;
I still have a short “wish” list:
When financially sound introduce a battery in the environment to further reduce energy consumption from the grid;
Keep an eye on traffic speed on the main road next to our house;
In general I’m in an optimization phase. Most use-cases are up and running and require regular tweaking and fine-tuning. Sometimes optimization means taking 10 minutes to change an algorithm and push the micro-service into production. Sometimes it means two weeks of (evening) work to fundamentally change the architecture of a use-cases. It’s a hobby project, it keeps me from the street and challenges my technical skills.
I migrated my system from an (unstable) NUC to a home-build AMD-based tower system with a little bit more space for cooling. After a couple of days the system crashed reporting I/O errors on the secondary NVMe.
After some investigation this seems to be related to a power saving mechanism that puts the NVMe (partially) to sleep. To disable this power saving mechanism I had to change this file /etc/default/grub:
The problem was of a SSD features, the Autonomous Power State Transitions(APST) was causing the freezes.
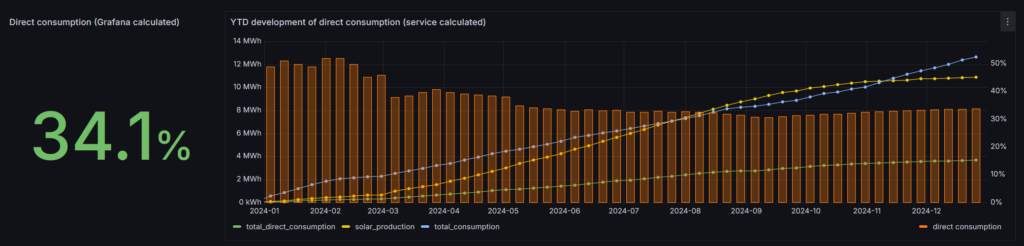
In October 2024 I analyzed the data YTD: Minimizing grid consumption (2). In the days after NYE I had another look at the data and noticed some irregularities. The algorithm that calculated the direct consumption percentage didn’t match with the values registered by my energy meters. I updated the algorithm and recalculated the data from 2024 to make it consistent with the values registered by the energy meters.
The good news is that things look better compared to analysis I did in October:
I closed the year with a direct consumption of 34.1%. This is a huge leap forward from the 19% in 2023! However, unfortunately I did not achieve my goal (40%).
First things first: where is the improvement coming from? As I mentioned in the previous blog, I spend my time on improving two things: car charging and heatpump planning.
Car charging
In total the car consumed roughly 6400kWh in 2024, of which 1730kWh were produced by solar energy.
(The “bump” in March was related to a service outage during our vacation and a correction of three weeks of missing data)
At this moment I’m planning the charging of the car based on an ON/OFF mechanism. The car is charged when most solar energy is expected. Then it will charge at 11kW (full speed). What I can still improve is to take the amount of expected solar energy into account, and adjust the charging speed accordingly. This will lengthen the charge and spread it out over the day, and probably result in a higher direct consumption, especially in the summer months.
Heatpump planning
The planning of the generation of domestic hot water was already operational for a longer time. I improved some small things in the algorithm, for example, setting the maximum power consumption of the boiler at disinfection runs depending on the availability of solar energy.
In total the heatpump consumed 2650kWh in 2024, of which 739kWh where produced by solar energy.
(The “bump” in March was related to a service outage during our vacation and a correction of three weeks of missing data)
In the last months of the year I made some minor adjustments to the planning of heating the house. As the isolation of our house is modern I can turn off the heatpump for a couple of hours without noticeable impact on the inside temperature. I’m reducing the set temperature during the night and turn off the heatpump during the six hours the EPEX energy prices are at their peak. As the heatpump is consuming a lot of energy during the winter period, when there isn’t a lot of solar energy anyway, I don’t think this will actually contribute to my main goal.
Conclusion
Unfortunately I wasn’t able to achieve my target, but I made a good step in the right direction. I made some small adjustments to the goals, hoping I can still achieve 50% direct consumption without using a battery system. As the “salderingsregeling” will end in 2027, it should still give me enough time to evaluate if there is a need for a battery system before 2027 starts.
When disks have exactly the same brand and type (this is quite normal on virtualisation platforms) Linux can mess up the logical assignment of these disks and swap, for example, sdb1 and sda1 after a reboot. To solve this we need to mount those disks based on their UUID.
Use the following command to retrieve the disk UUID:
Last year, I described my view on home energy consumption and my personal goals here: minimizing grid consumption.
Today, the summer of 2024 has passed and we’re moving into the “dark” season. It’s time to look ahead towards the end of the year, look back at my previous goals and adjust them where necessary.
Before we do that let’s have another look at my ambitious goals for the next years:
Year
Grid consumption
Direct consumption
2023 (today)
80%
20%
2024
60%
40%
2025
53%
47%
2026
50%
50%
Overview of yearly goals to reach my vision in 2027 (defined in December 2023).
Status quo
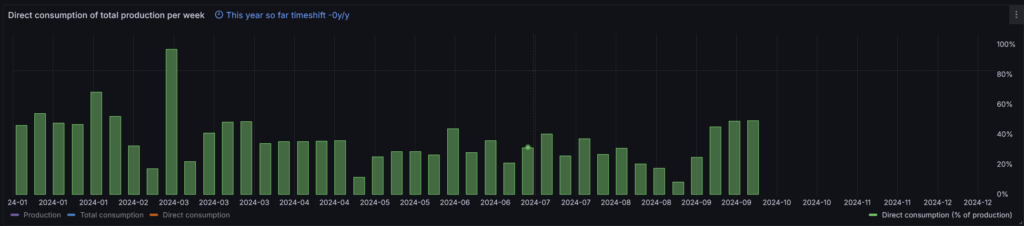
At the end of 2023 roughly 20% of the energy we consumed was directly consumed from our solar panels. Today, in the beginning of October 2024, our direct consumption of the year 2024 (year-to-date) is 28.4%.
A weekly overview of the direct consumption (0-100%).
The start of the year seemed good. However, in the beginning of the year the solar panels deliver less energy compared to the summer months, so the direct consumption is higher in the “dark” months. In the end, I’m far away from the 40% I was hoping to achieve this year.
Changes
This was not totally unexpected, but still a bit of a disappointment. Especially considering the changes I’ve worked on during the year:
Introduction of a price index
I was already monitoring the epex-spot prices and predicting the production of solar energy. I used both data points to schedule energy consumption, but the algorithm was (too) complex to maintain and wasn’t always showing optimal results. I’ve created a price-index that combines the epex-price and expected solar production into a single value.
Energy planning using the price index
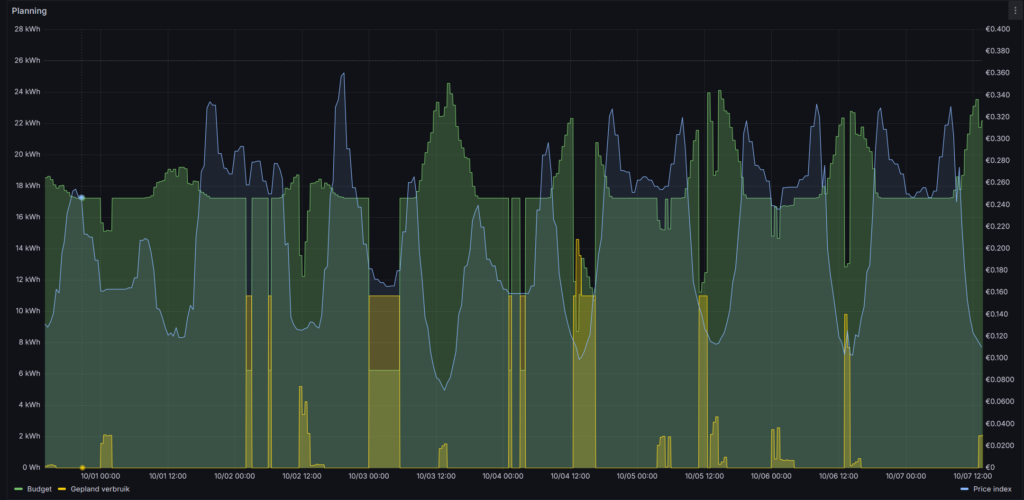
To use the price-index I needed to adjust the scheduling process. This was a difficult change because appliance specific micro services where doing their own planning. This meant I needed to change the “controllers” for the HomeConnect appliances, heatpump and car. I took this as an opportunity to create a separate scheduling micro service. The controllers now request the scheduling service for the best time to start a appliance specific program. The scheduler calculates the best start time based on the expect program duration, consumption and time to complete. The image below visualizes the result of the new scheduler process. Most programs are scheduled during the daily solar peak, when the price index is at it lowest point. However, when I get home from work at the end of the afternoon, and need to start driving early morning again, the scheduler uses the price index to chose the best time to charge the car during the night.
Visualization of the planning process: (green) available energy grid+solar; (blue) price-index; (yellow) planned energy consumption.
Unplanned car charging
When I don’t know when I need the car I just connect it to the socket. The controller then considers the actual solar production and redirects this energy to the car. To ensure a stable charging process I needed to build in some delays. The curve is not perfect, but I think it’s close enough.
(Orange) solar production; (green) car charging.
There is some discussion on the impact of the power quality of “smart charging”. I need to understand this a bit better and probably need to adjust my algorithm.
What’s going on?
Why am I stuck at 28%? To answer this question I need to look at the two largest consumers: the car and the heatpump.
Car
Let’s start with the car: the direct consumption of the car is 31%. It will be very difficult to further improve this, as it’s depending on a combination of my work schedule and the weather. The situation has improved since the beginning of the year. I’m expecting the year end to be difficult as the solar production will go down in the last months of the year. I might be able to find small optimizations in the scheduler over the next months.
31% of the car energy consumption is coming from solar production.
Heatpump
The heatpump is even more complex as it uses two energy sources (the compressor and the COP1 heater) and has three different goals: heating, cooling, and domestic hot water. For this analysis I have only looked at the difference between the compressor and the COP1 heater.
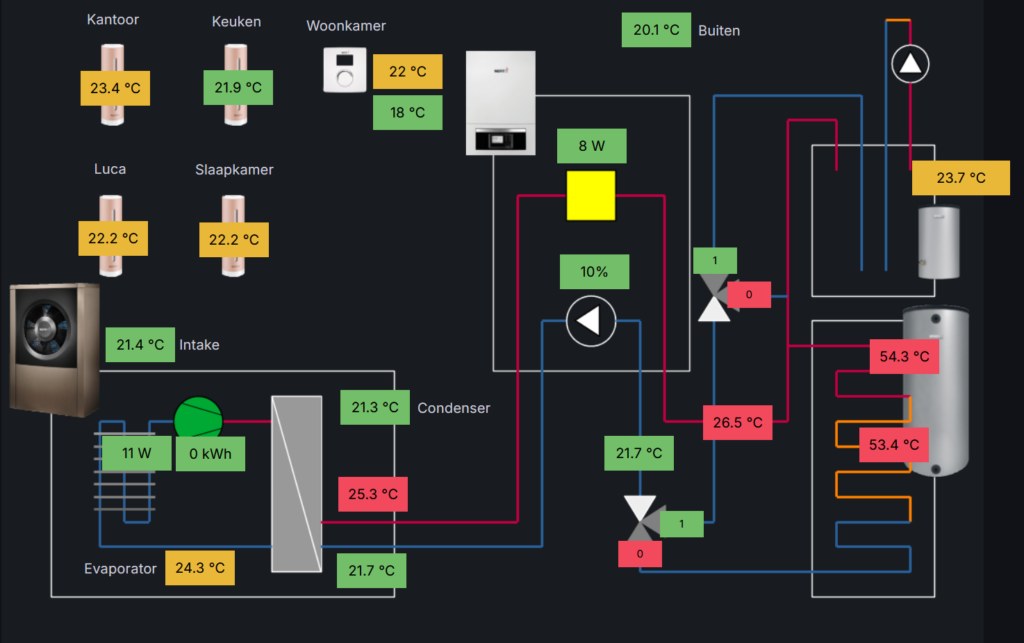
The digital twin of the heatpump was already operational at the end of 2023. It gives me full control of when domestic hot water, disinfection, heating and cooling are enabled.
Digital twin of the heatpump
I’ve started to work on a couple of things:
Detailed planning of the generation of domestic hot water;
Detailed planning of the disinfection process (to prevent bacteria);
Reducing the operation hours of the heating and cooling process.
The domestic hot water is now only generated during the day, based on the price index. The scheduler does not wait until the hot water is “empty”, but starts generating hot water if it expects a sunny day to generate a buffer for the day after.
The disinfection is typically planned once a week. I needed to add a bit of slack and, depending on the predicted availability of solar energy, it now schedules the best time to run a disinfection run between 6-9 days after the last run. Additionally, the power of the disinfection is adjusted based on the maximum available solar energy. If a maximum of 3kW of solar energy is expected, the disinfection power is adjusted down from 9kW to 3kW, it’s lowest value. The disadvantage is that disinfection takes longer, but that has not proven to create new problems.
Last winter, the heatpump was running the entire night to heat the house. Then, on sunny days, the sun started heating up our living room through our glass “walls” resulting in an inside temperature of 25 degrees Celsius. The energy consumed by the heatpump in the night and morning was, more or less, wasted. The controller now looks at the predicted temperature and solar radiation of the upcoming day and only turns on the heatpump if a combination of a low temperature and low sun radiation is expected. Cooling is only enabled if the inside temperature reaches a configured threshold. This mechanism should prevent wasted energy, but is not optimized for generating heat a the best time of day.
This has resulted in 20% direct consumption, which is far from the target.
Direct consumption of the heatpump 2024 YTD.
The largest problem is the heating in the winter. There is no solar energy produced so the direct consumption is low.
When I only look at the direct consumption over the last 90 days (7 Juli – 7 October) the situation looks a lot better.
Direct consumption of the heatpump over the last 90 days.
Conclusion
I don’t think the 40% direct consumption target is realistic for 2024. I probably need another year to come to 40%.
Over the next months I need to start understanding in which situations the heatpump is consuming energy from the grid. Additionally, I will slowly start looking into the consumption and planning of the WTW (ventilation) unit, fridge, and freezer. At the same time I need to prevent the risk of food poisoning by (control) software failure.
systemctl --type swap
UNIT LOAD ACTIVE SUB DESCRIPTION
dev-sda3.swap loaded active active Swap Partition
systemctl mask dev-sda3.swap
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
reboot
Configure contianerd so that it works with Kubernetes:
containerd config default | tee /etc/containerd/config.toml >/dev/null 2>&1
Both the kubelet and the underlying container runtime need to interface with control groups to enforce resource management for pods and containers and set resources such as cpu/memory requests and limits. To interface with control groups, the kubelet and the container runtime need to use a cgroup driver. Set cgroupdriver to systemd (true) on all the nodes:
Install Kubernetes cluster with Kubeadm. Kubelet doesn’t appreciate the command-line options anymore (these are deprecated). Instead, I suggest to create a configuration file, say ‘kubelet.yaml’ with following content.
Create the kubelet.yaml file on the master node (K8S01):
nano kubelet.yaml
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: "1.30.0" # Replace with your desired version
controlPlaneEndpoint: "K8S01"
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
Initialise the cluster:
kubeadm init --config kubelet.yaml --upload-certs
Result:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join k8s01.verhaeg.local:6443 --token 965cpz.xvmun07kjrezlzg9 \
--discovery-token-ca-cert-hash sha256:3ea38e43e5304e0124e55cd5b3fb00937026a2b53bc9d930b6c2dab95482225a \
--control-plane --certificate-key e48ada5b6340b8e217bcf4c7c5427ae245704be43eee46c07bfa0b6e1c4abdd8
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8s01.verhaeg.local:6443 --token 965cpz.xvmun07kjrezlzg9 \
--discovery-token-ca-cert-hash sha256:3ea38e43e5304e0124e55cd5b3fb00937026a2b53bc9d930b6c2dab95482225a
To start interacting with cluster, run following commands on master node,
root@K8S01:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s01 NotReady control-plane 62s v1.28.11
k8s02 NotReady <none> 26s v1.28.11
k8s03 NotReady <none> 21s v1.28.11
Install Calico (container networking and security):
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.